
Find largest n directories in Linux
I have been working a lot on Linux the last couple of months. And I don't mean Linux with a nice front end, I mean from the command line. Please note my Linux experience is/was basically zero, and mostly involved getting in touch with a Linux administrator friend of mine (let us call him Linux Administrator from Heaven or LAFH). So the learning curve has been steep, but well worth it.
So the problem this morning was the lack of space on one of the nodes in our cluster. Awesome. So back in Windows world, TreeSize gets installed, a scan is started, and you clean up based on the results from TreeSize.
Slight problem with the command line; it is not great at showing pretty trees.
So after googling around (and not getting in touch with LAFH for a change), I found the following command:
find . -type d -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
(Spoiler alert, the command above works!)
At first glance, the command is quite intimidating, but when broken down into smaller pieces, it becomes easier to understand.
So here goes:
find . -type d -print0- Find all directories in current directory
xargs -0 du- Take the result from find and build command line to pass to the du command. So basically take each directory and pass it's name to the du command to get the disk usage for the directory
sort -n- Take the result from the du command and sort according by numerical value
tail -10- Takes the last 10 results from the sort command
cut -f2- Takes the result from the tail command, and takes the second field from the result set
xargs -I{} du -sh {}- Takes the second field extracted via the cut command and pass it to the du command
The magic ingredient bringing all the subcommand together is the | (pipe) operator. The pipe operator chains a set of command together by taking the output of a command and feeding it to the next command.
Below is a more visual explanation of how the command as a whole works when broken down into the subcommands.
Imagine a directory structure as shown below:

Breaking the command up into each step we can see the how the commands build on top of each other to give us the required result
find . -type d -print0: Prints (-print0) all the directories (-type d) next to each other

find . -type d -print0 | xargs -0 du: Prints the directory name and size in bytes (du)
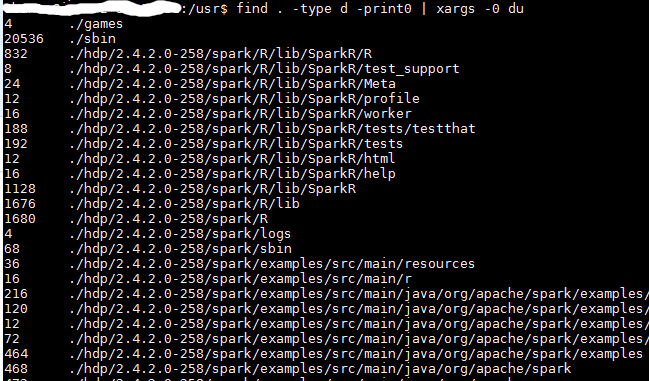
find . -type d -print0 | xargs -0 du | sort -n: Sorts (sort -n) the results numerical based on the size of the directory

find . -type d -print0 | xargs -0 du | sort -n | tail -10: Takes the last (tail) 10 (-10) entries based on the size of the directories

find . -type d -print0 | xargs -0 du | sort -n | tail -10 | cut -f2: Cuts (cut) the second field (-f2) from the tail result

find . -type d -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}: Takes the name of the directory from the cut command, and pass the name to the du command via xarg to get the size (du)of each directory in human readable form (-sh)
